Some of unicode problems
Table of Contents
Some of text problems or some of falsehoods#
A long time ago, I came across a wonderful list of things Falsehoods Programmers Believe and Falsehoods Programmers Believe About Falsehoods Lists
Now its time to update some knoleage about it
Text is everything.

During my life, text has been a major source of information. In my work, I have regularly encountered the nuances of storing textual information, from illegibly written text and messy layout and fonts in a Word document to the processing of streaming data
In 2008, the following story happened A Cellphone’s Missing Dot Kills Two People, Puts Three More in Jail
Or how the Wubi Effect is affecting Chinese language
Internationalis(z)ing Code - Computerphile - About the difference in languages according to gender, number and place in a sentence; dates and numbers
Piękna gra typografią i brzmi trochę jakby Czech rapował - In 2010, Polish musicians Łona and Webber wrote a short composition and demonstrated how the Polish language sounds without diacritical marks.
unicode vs html Think about all the things they’ve told you that you 𝑛𝑒𝑒𝑑. HTML is NOT the answer!
And character Set Issues by A.J. Flavell “i18n: HTML Character set issues beyond HTML3.2”
So there is no doubt about the importance of textual information
For example, here are a couple of articles with lists of misconceptions that are true not only for programmers
What about standarts?
Unicode#
Unicode is a big table that assigns numbers (codepoints) to a wide variety of characters you might want to use to write text. We often say “Unicode” when we mean “not ASCII”, but that’s silly since of course all of ASCII is also included in Unicode.
There are already plenty of introductions to Unicode floating around (wikipedia, nedbat, joel).
UTF-8 is an encoding, a way of turning a sequence of codepoints into bytes. All Unicode codepoints can be encoded in UTF-8. ASCII is also an encoding, but only supports 128 characters, mostly English letters and punctuation.
A character is a fairly fuzzy concept. Letters and numbers and punctuation are characters. But so are Braille and frogs and halves of flags. Basically a thing in the Unicode table somewhere.
Unicode refers to these numbers as code points.
Since everybody in the world agrees on which numbers correspond to which characters, and we all agree to use Unicode, we can read each other’s texts.
Currently, the largest defined code point is 0x10FFFF. That gives us a space of about 1.1 million code points.
About 170,000, or 15%, are currently defined. An additional 11% are reserved for private use. The rest, about 800,000 code points, are not allocated at the moment. They could become characters in the future.
Here’s roughly how it looks:
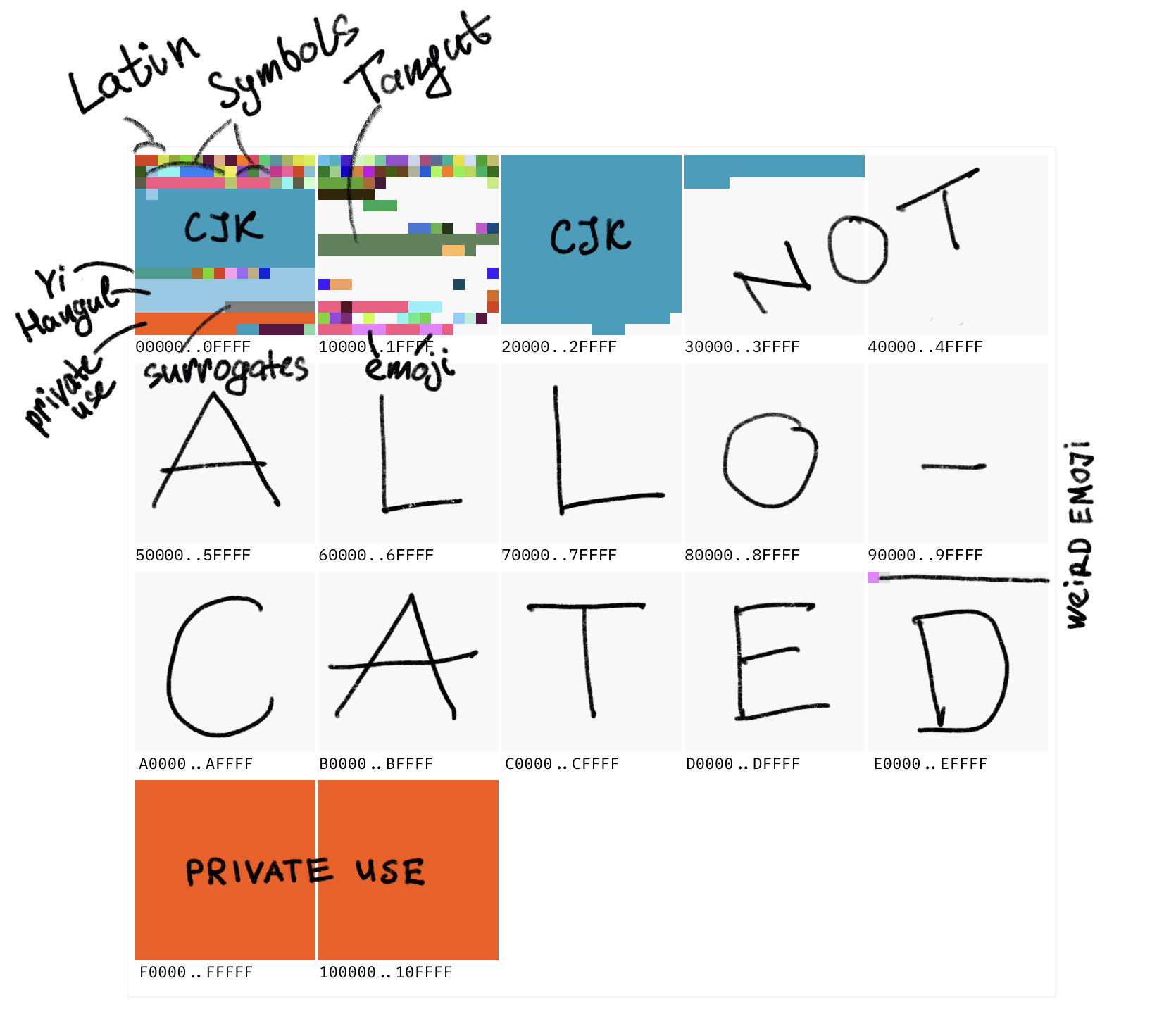
Private Use?#
These are code points reserved for app developers and will never be defined by Unicode itself.
For example, there’s no place for the Apple logo in Unicode, so Apple puts it at U+F8FF which is within the Private Use block. In any other font, it’ll render as missing glyph , but in fonts that ship with macOS, you’ll see .
Principles of the Unicode Standard#
The Unicode Standard set forth the following fundamental principles:
- Universal repertoire - Every writing system ever used shall be respected and represented in the standard
- Logical order - In bidirectional text are the characters stored in logical order, not in a way that the representaion
- Efficiency - The documentation must be efficient and complete.
- Unification - Where different cultures or languages use the same character, it shall be only included once. This point is
- Characters, not glyphs - Only characters, not glyphs shall be encoded. In a nutshell, glyphs are the actual graphical
- Dynamic composition - New characters can be composed of other, already standardized characters. For example, the character “Ä” can be composed of an “A” and a dieresis sign (“ ¨ ”).
- Semantics - Included characters must be well defined and distinguished from others.
- Stability - Once defined characters shall never be removed or their codepoints reassigned. In the case of an error, a codepoint shall be deprecated.
- Plain Text - Characters in the standard are text and never mark-up or metacharacters.
- Convertibility - Every other used encoding shall be representable in terms of a Unicode encoding.
Even email#
Are you sure that your email validation is right? I Knew How To Validate An Email Address Until I Read The RFC Your E-Mail Validation Logic is Wrong does next emails valid
Joe.\\Blow@example.com
"jd..oe"@domain
" "@netmeister.org
"<>"@netmeister.org
"put a literal escaped newline here\ <--"@domain
mail -s "a very long To" $(perl -e 'print "a" x 526;')@netmeister.org
"josé.arrañoça"@domain
"сайт"@domain
"💩"@domain
"🍺🕺🎉"@domain
poop@xn--ls8h.la
poop@💩.la
"🌮"@i❤️tacos.ws
jschauma@شبكةمايستر..شبكة
jschauma@[166.84.7.99]
jschauma@[IPv6:2001:470:30:84:e276:63ff:fe72:3900]
jschauma@[IPv6:::1]
"[IPv6:::1]"@[IPv6:::1]
@1st.relay,@2nd.relay:user@final.domain
and Alla.jd.Doe@domain.com same as alla.jd.doe@domain.com and .toLower(
Alla.jd.Doe@domain.com)?
twitter bulgarian issue
https://x.com/nikitonsky/status/1171115067112398849?s=20
Text is everything.
Even colors have a textual representation#
OKLCH в CSS: почему мы ушли от RGB и HSL and
and couple of instruments to work with colour:
Fonts is everywhere#
https://github.com/RoelN/Font-Falsehoods
More links about fonts:
- https://type.today DrawBot Шрифт Beowolf https://www.fontshop.com/families/ff-beowolf Вариативные шрифты https://v-fonts.com/ Курсы по шрифтам: https://www.typedesignworkshop.org/ru http://bolditalic.type.school/ шрифты: Trinité и Lexicon дизайнера Bram de Does
https://monaspace.githubnext.com/
https://developer.apple.com/sf-symbols/ - vWith over 5,000 symbols, SF Symbols is a library of iconography designed to integrate seamlessly with San Francisco, the system font for Apple platforms. Symbols come in nine weights and three scales, and automatically align with text. They can be exported and edited using vector graphics editing tools to create custom symbols with shared design characteristics and accessibility features. SF Symbols 5 introduces a collection of expressive animations, over 700 new symbols, and enhanced tools for custom symbols.
Case is also a broblem#
For example there are more than two cases. Unicode actually has three cases. There’s lowercase, and there’s uppercase. And there’s titlecase.
- A character is uppercase if its general category is Lu (“Letter, uppercase”), and lowercase if its general category is Ll (“Letter, lowercase”). The Unicode Standard admits this is a very limiting definition, because each character gets only one general category, so many characters which “should be” uppercase or lowercase may fail this definition on account of their general category indicating something else.
- A character is uppercase if it has the derived property Uppercase, and lowercase if it has the derived property Lowercase. These are based on combining the characters in definition (1) with characters possessing other properties which indicate case.
- A character is uppercase if applying the Unicode case mapping to uppercase (“uppercasing it”) leaves it unchanged, and lowercase if applying the Unicode case mapping to lowercase (“lowercasing it”) leaves it unchanged. This is comprehensive, but may also behave unintuitively (see later sections).
Meanwhile some characters have no case
A character C is defined to be cased if and only if C has the Lowercase or Uppercase property or has a General_Category value of Titlecase_Letter.
Some characters may appear to have multiple cases
Read more in Falsehoods about case
Case is context-locale-sensitive
String length is typically determined by counting codepoints. This means that surrogate pairs would count as two characters. Combining multiple diacritics may be stacked over the same character. a + ̈ == ̈a , increasing length, while only producing a single character.
Similarily, reversing strings often is a non-trivial task. Again, surrogate pairs and diacritics must be reversed together. ES Reverser provides a pretty good solution.
Upper and lower case mappings are not always one-to-one. They can also be:
One-to-many: (ß → SS ) Contextual: (…Σ ↔ …ς AND …ΣΤ… ↔ …στ… ) Locale-sensitive: ( I ↔ ı AND İ ↔ i )
Do not forget about text rendering#
More Reading#
More Awesome-Unicode
W.T.F. Japan: Top 5 most insane kanji place names in Japan【Weird Top Five
Great text about unicode in 2023 https://tonsky.me/blog/unicode/ And https://hsivonen.fi/string-length/
It’s Not Wrong that “🤦🏼♂️”.length == 7
Breaking Our Latin-1 Assumptions
- The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets - By Joel Spolsky
- What Every Programmer Absolutely, Positively Needs To Know About Encodings And Character Sets To Work With Text
- The Unicode Consortium’s Recommended Reading List
- Space Yourself - Smashing Magazine’s Spacing Guide
- JavaScript has a Unicode Problem
- Creative usernames and Spotify account hijacking